第三章 / 共六部分
智能开始生产智能
第三条曲线最强的形态,是更强 AI 开始参与制造下一轮更强 AI。
第三章
《复利的第三范式》第三章
前两章说到这里,第三条复利曲线还只是工具层命题:AI 系统能够保存上下文,接收反馈,沉淀经验,并把本轮任务变成下一轮任务的条件。这个判断已经足够重要,但还不是最强的部分。真正让 AI 复利区别于普通工具复用的地方,在于它可能进入一个更深的回路:智能开始参与生产下一轮智能。传统工具很少做到这一点。一台机床可以制造零件,但通常不会自己重新设计下一代机床;一套软件可以提高工程师效率,但软件本身并不自动完成下一代软件体系的研究。人类当然可以借助工具改造工具,但关键的抽象、判断、实验设计和错误归因,长期仍由人承担。工具放大了研究者,却没有成为研究者群体的一部分。
AI 的断点在这里。一个足够强的模型,回答问题之外,还可以读论文、写代码、生成实验方案、分析训练日志、寻找 bug、比较架构、生成合成数据、做自动评估、提出优化方向。它一旦进入 AI 研发流程,能力提升就不再只来自外部人类研究者的缓慢积累,而开始部分来自智能系统对自身生产条件的改造。模型能力提高,会让 AI 研发更快;AI 研发更快,又会带来更强模型。这是一种比普通使用复利更激烈的结构。第二章讨论的是“任务经验能否回到工具系统”,本章讨论的是“智能能力能否回到智能生产系统”:一个改变工作流,一个改变能力增长本身。
这也是为什么 scaling law 和复利之间可以建立桥。Scaling law 不是金融复利,它描述的是规模投入和模型能力之间相对可预期的关系。算力、数据、参数、训练方法、推理时计算和后训练技术共同推动能力曲线上移。只要这种关系没有彻底断裂,模型能力就会随着有效规模继续推进。真正的问题在于:当模型本身开始参与提高有效规模,曲线就不再只是“人类投更多资源,模型变强”,而变成“更强模型帮助人类更快地制造更强模型”。这时,scaling law 提供底层斜率,AI 研发自动化提供斜率继续变陡的机制。
这里可以借用一个更克制的说法:AI 的复利有两层。第一层是模型层的规模复利,来自算力、数据和算法效率的持续推进。第二层是研发层的递归复利,来自 AI 进入研发流程之后,对算法、数据、评估、工程和工具链的反向改造。第一层让模型变强,第二层让“变强这件事”本身变快。两层叠在一起,才构成从 AGI 走向更强智能系统时最值得警惕的结构。它不要求每一步都出现奇迹,只要求很多环节都能被压缩一点:实验更快,代码更快,评估更快,数据生成更快,架构搜索更快,工程排障更快。
所谓 AGI 到 ASI 的想象,不能只被理解成一个模型突然越过某条神秘边界。更关键的变化,是足够强的 AI 变成大规模研发劳动力。它可以同时运行很多副本,可以在不同方向上试错,可以昼夜不停地改进代码和实验,可以把人类研究者过去数年才能铺开的搜索空间压缩到更短时间里。即使每一个 AI 研究员都并非天才,只要数量、速度和反馈密度足够高,系统层面的研发能力也会发生质变。过去,一个实验室的进步依赖有限研究者的注意力;未来,研究者的判断可能仍然重要,但大量中间劳动会被外部智能系统吸收。
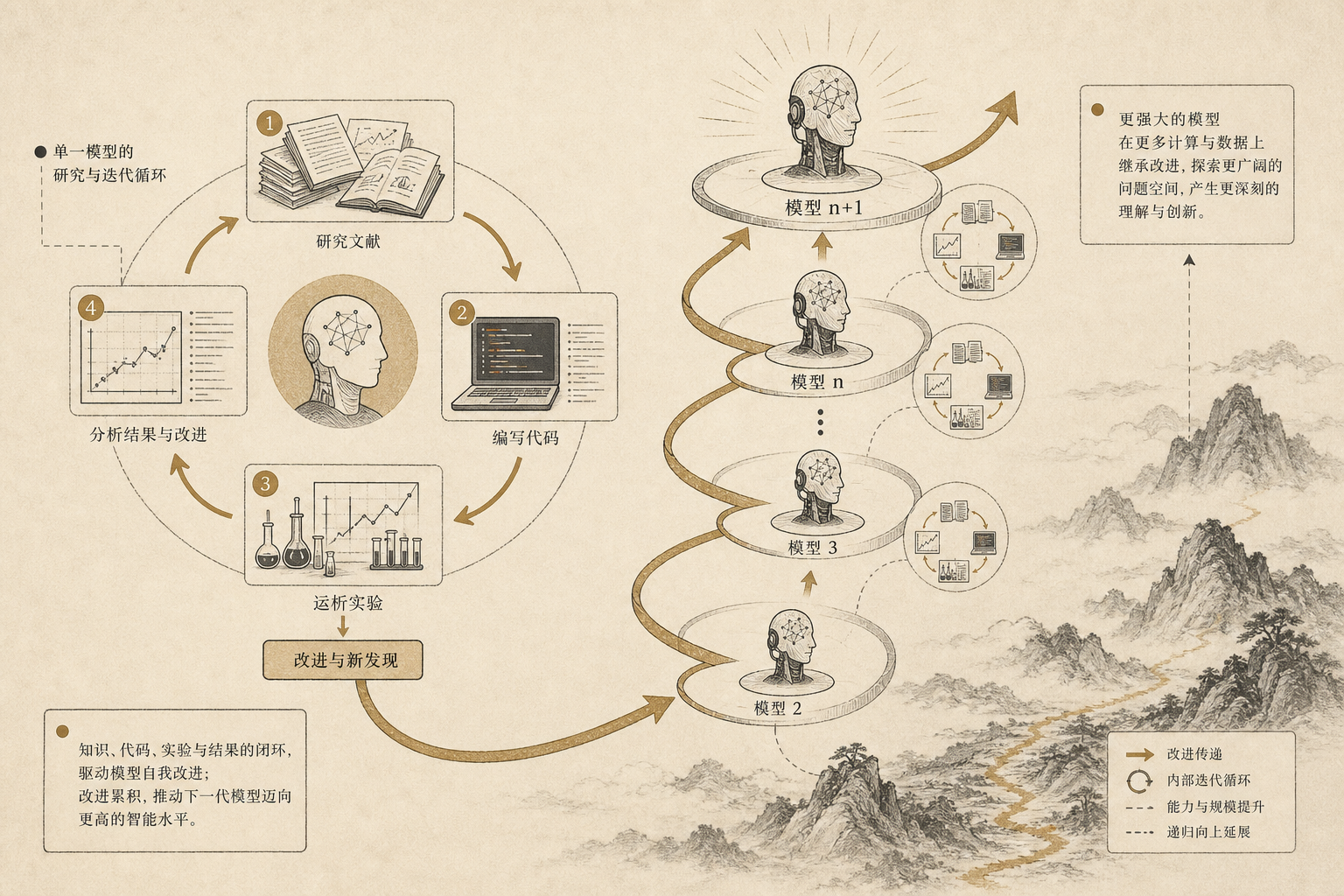
这种变化最容易先发生在 AI 研发本身,因为 AI 实验室最知道自己的工作如何被拆解、评估和自动化。训练脚本、模型评估、数据清理、推理优化、benchmark 设计、失败日志分析、代码重构、并行实验调度,这些任务都处在高度数字化的环境里。一个能力足够强的 agent 不需要拥有完整科学直觉,也能在这些环节创造实际加速度。更重要的是,这些环节的收益会再次回到模型生产过程。一个更好的评估体系,会帮助筛掉错误方向;一个更高效的训练框架,会释放更多实验预算;一个更便宜的推理方案,会让更多自动研究副本运行起来。
这里还要补上“解束”的一层。模型从聊天框里的问答系统,变成能使用工具、调用代码、长程规划、读取文件、维护记忆、执行任务的 agent,本身就是一次能力释放。很多能力已经存在于模型的内部表示里,但在纯聊天形态下被限制在短对话和单次输出中。一旦模型获得更长上下文、更可靠工具调用、更强推理循环和更稳定的执行环境,它的实际产能会显著高于静态 benchmark 给人的印象。换句话说,第三条曲线不只来自模型参数变大,也来自模型被放进更长的行动回路。
这种递归并不意味着无限加速一定发生。现实里会有瓶颈:实验需要算力,数据需要质量,评估可能失真,真实世界反馈有延迟,硬件制造无法像软件一样瞬时复制,组织决策也会拖慢节奏。更强模型未必自动知道哪个研究方向正确,自动化实验也可能制造大量噪音。复利不是魔法,它只说明本轮能力可以进入下一轮能力的生产过程。至于曲线能抬多高,仍取决于瓶颈在哪里。真正严肃的预判,应该同时看到递归加速的可能和这些硬约束的存在。
但即使承认这些瓶颈,结构变化仍然非常大。过去,AI 进步主要受限于少数顶级研究者、工程团队、算力预算和实验周期。现在,智能系统本身开始承担一部分研究劳动。它不需要完整替代科学家,只要能持续提高研究流程里的某些环节,整个系统的有效研发速度就会改变。代码更快,实验更多,评估更密,工具链更自动化,模型迭代的节拍就可能被重新设定。人类研究者仍然提供方向、判断和边界,但他们所在的生产系统已经不再是纯人类研究系统。
万亿级集群的意义也应放在这个位置理解。它把更大的硬件投资,转化为智能生产智能回路的工业化。巨型数据中心提供训练和推理算力,资本为下一轮模型押注,能源和芯片成为新的战略基础设施,研究流程被自动化系统包围。资本复利、算力扩张、算法效率和 AI 研发自动化开始彼此咬合。第三条曲线由此离开个人工作流里的模板沉淀,进入整个 AI 工业系统的连续生产。这个系统已经超出“一个模型变强”的范围,成为资本、能源、芯片、数据、模型、工具链和自动研究劳动共同形成的加速装置。
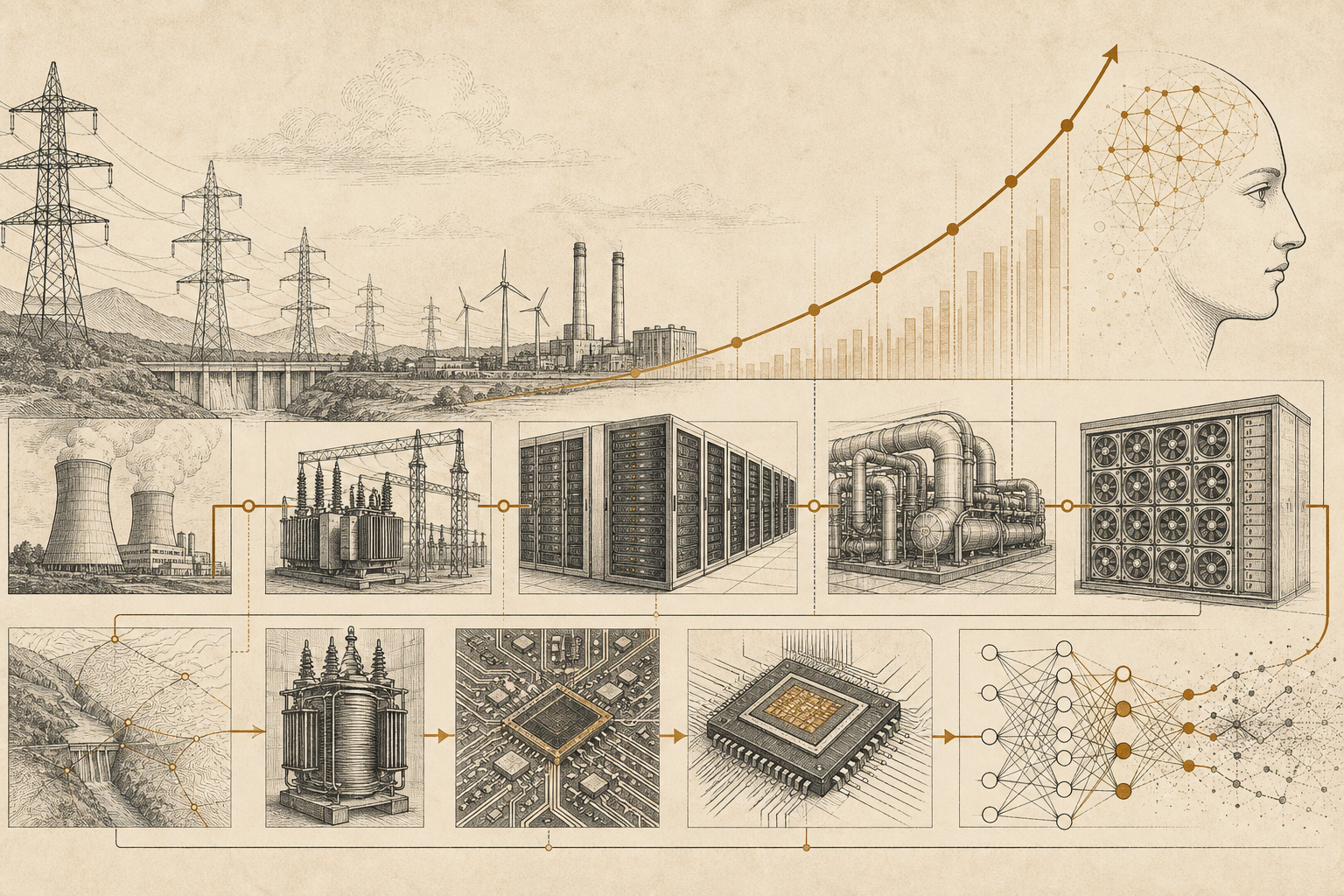
这也是为什么“超级复利”的说法虽然夸张,却有它试图捕捉的现实对象。普通复利是收益回到本金;AI 递归复利是智能能力回到智能生产系统。普通技术进步通常依赖人类把新工具应用到下一轮研发;AI 之后,工具本身可能承担越来越多下一轮研发劳动。这里的质变,不在于某个模型是否已经拥有人的全部能力,而在于智能劳动是否开始变得可复制、可并行、可调度、可评估、可投入到自身改造之中。
因此,本章的关键判断是:AI 复利最强的形态,发生在智能进入智能的生产过程之后。传统工具提高人的产能,AI 有可能提高“提高产能的能力”。一旦这一点成立,第三条复利曲线就从普通工具效率问题,变成一条关于未来智能增长速度的预判曲线。后面真正需要追问的,是当这条曲线外溢到软件、科研、制造、教育、金融和治理时,整个人类社会会怎样被接入这种新的增长结构。