Open Typeless Harness
一种 correction-native 的语音输入方式,从你真实做出的编辑中学习个人词汇。
结论先行
GitHub: OpenCodexLabs/open-typeless-harness.
Open Typeless Harness 来自一个简单挫败感:通用 speech-to-text 总是在那些对你最重要的词上失败。项目名、论文术语、产品名、中英混合短语和个人写作习惯,恰好是普通 dictation 最笨的地方。
这个项目问的是另一个问题:如果语音输入能从文本落地后你实际做出的编辑里学习,会怎样?
为什么需要它
痛点不是 dictation 犯了一次错,而是它明天还会犯同样的错。你说一个 repo 名,修一次;说一个论文缩写,修一次;中英混说,再修一次。系统完全看不到这些 correction history。
这意味着用户手动变成了学习循环。每一次 correction 都是一个微小训练信号,但普通语音输入会把它丢掉。

核心想法
语音输入不应该是一个单独的写作框,而应该是覆盖在你已有工作字段上的输入层。你在当前 App 里说话,让模型 polish transcript,把它插入当前 focused field,然后观察短窗口内跟随发生的编辑。
这些编辑才是真正的产品信号。稳定 correction 可以成为本地 speech skills;模糊 correction 可以保持可审阅。这个 loop 会变好,但不要求用户变成 prompt engineer。
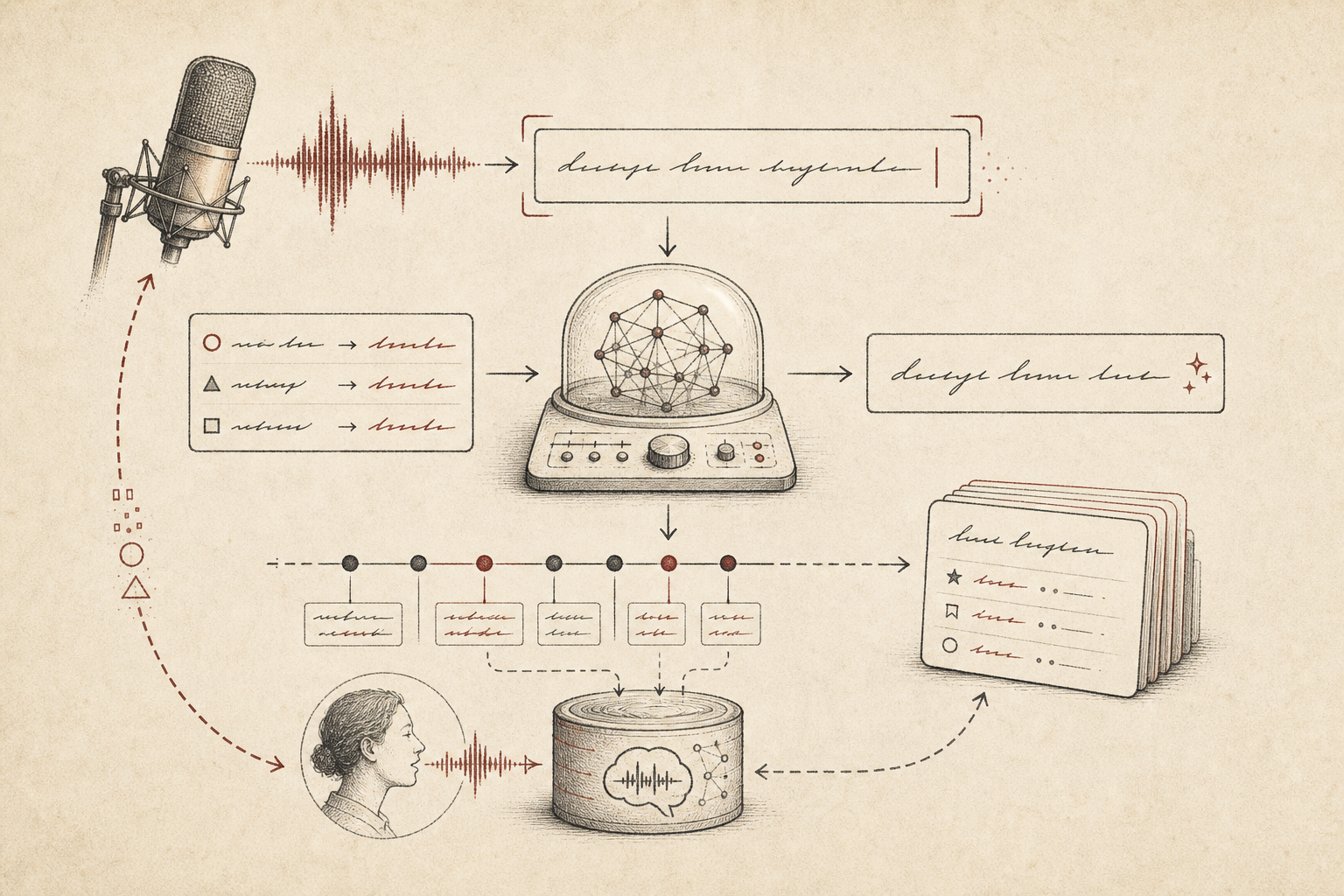
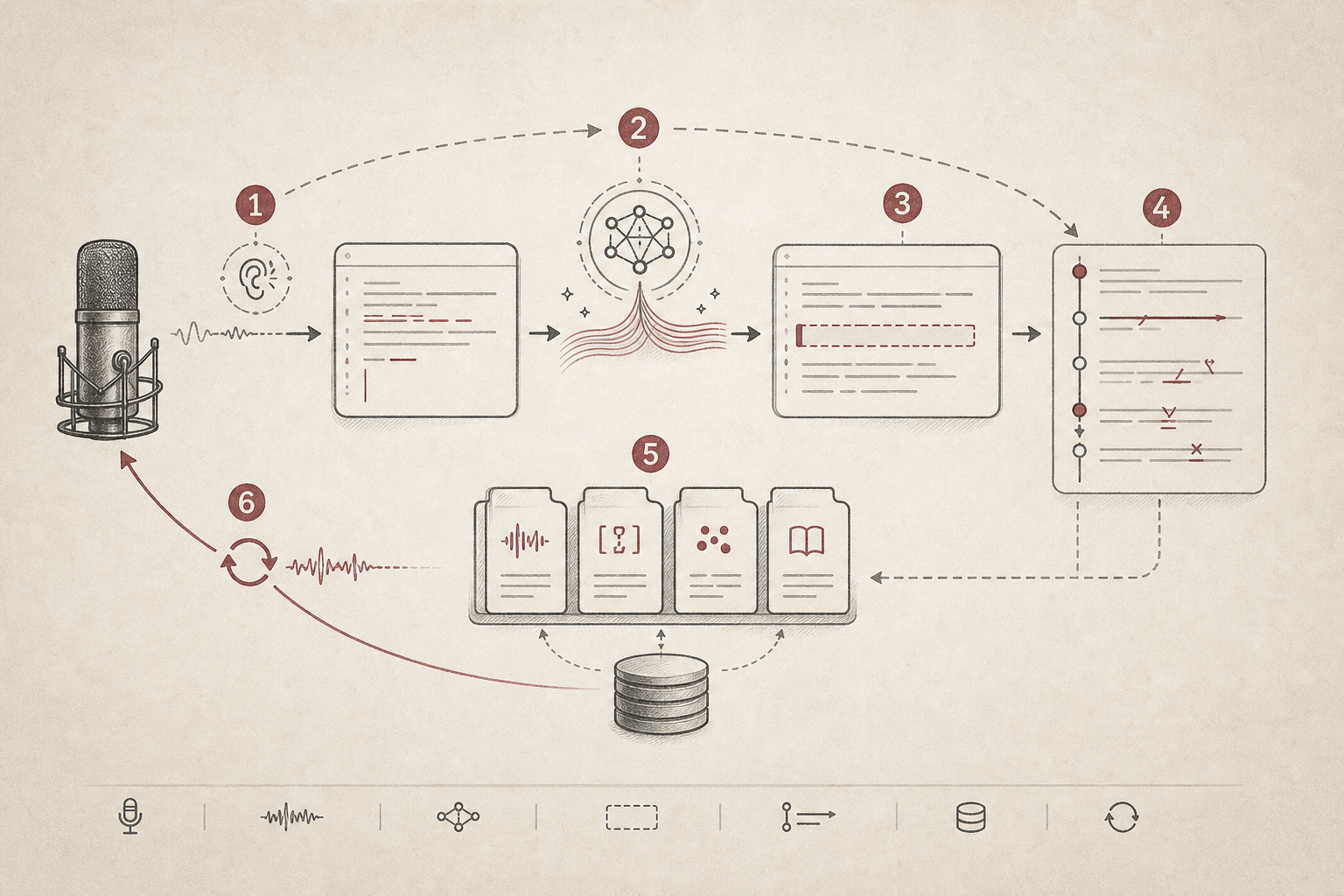
| 阶段 | 发生什么 | 为什么重要 |
|---|---|---|
| Listen | 捕获语音并生成 ASR transcript。 | 用户可以留在当前写作上下文中。 |
| Polish | 使用相关 speech skills 和 LLM polish step。 | 个人词汇可以在插入前被应用。 |
| Insert | 把文本写入当前 focused field。 | App 像输入层,而不是另一个编辑器。 |
| Learn | 观察插入后的短窗口编辑。 | 真实 correction 成为产品反馈。 |
| Adapt | 把稳定模式提升为本地 speech skills。 | 下一次 dictation 可以改进,而不需要手动调 prompt。 |
工作流
这个 workflow 是一个反馈循环:listen、polish、insert、learn、adapt。每一步都很小,但合在一起就把产品类别从 “speech-to-text” 变成了 correction-native input。
重要边界是:它仍然是输入层,不是自主 agent。它应该写入用户正在使用的字段,从用户编辑中学习,并把本地词汇控制权留给用户。
为什么重要
AI-native work 不只是让 agent 操作文件,也包括改变人表达意图的方式。语音带宽很高,但前提是系统理解个人词汇和上下文相关表达。
Open Typeless Harness 让语音输入不再像一次性转写服务,而更像一种会随着使用而改进的本地写作习惯。
什么时候使用
| 适合使用 | 需要小心 |
|---|---|
| 你经常口述技术内容或中英混合内容。 | 目标字段包含你不想被监控的私密文本。 |
| 你反复纠正同样的词汇错误。 | 你需要严格的法律、医疗或金融转写。 |
| 你想在现有 App 内使用语音输入。 | 一个简单快捷键已经足够完成任务。 |
一句话故事
语音输入不应该止步于 transcription。更有意思的产品 primitive 是 correction loop:用户修了什么,哪些修正反复出现,哪些应该变成本地 skill?
Open Typeless Harness 把 dictation 变成一个由真实编辑驱动的本地学习循环。