🚀 Selected Works [Google Scholar]
* Equal contribution, † Project Leader, ‡ Corresponding author
|
|
|
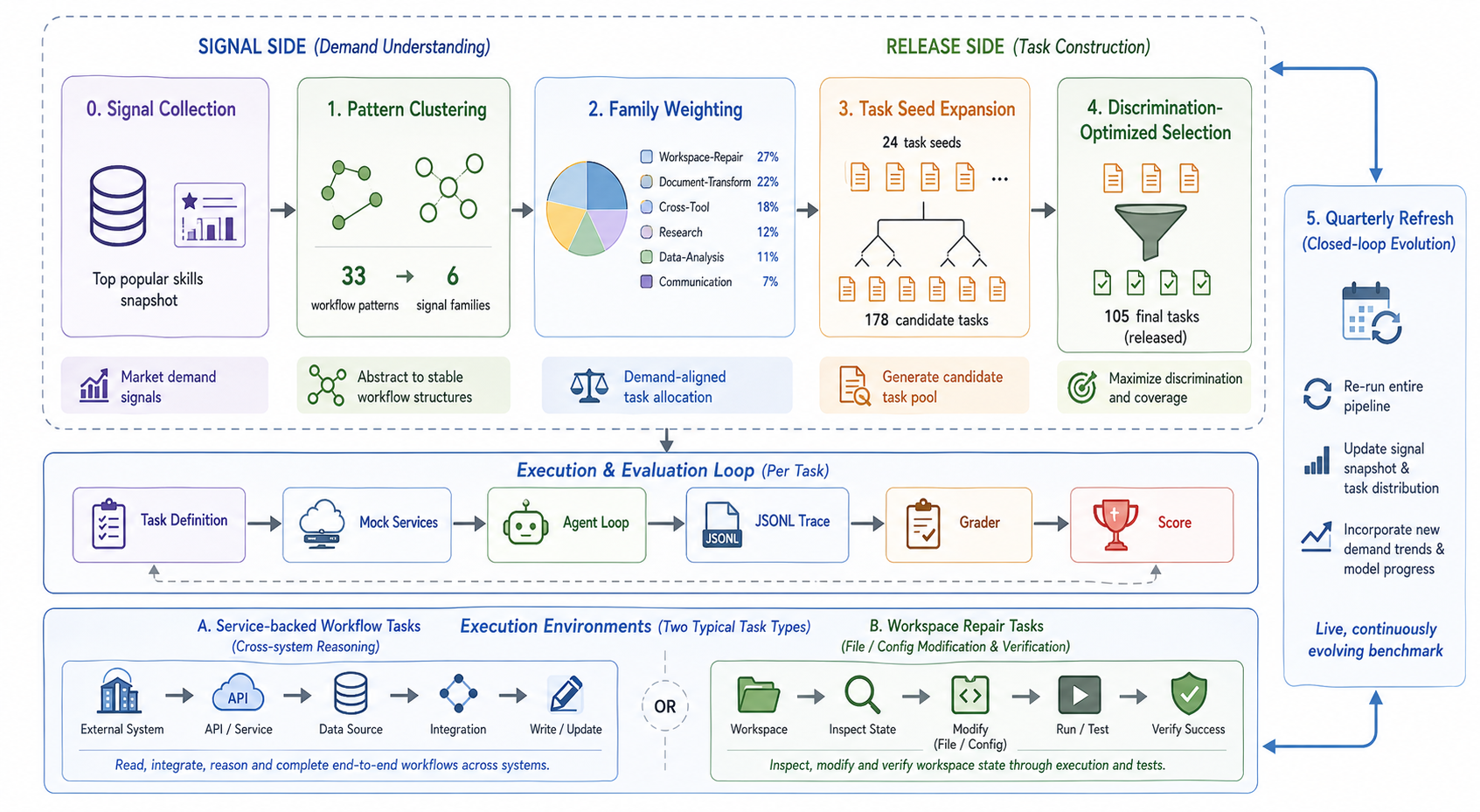
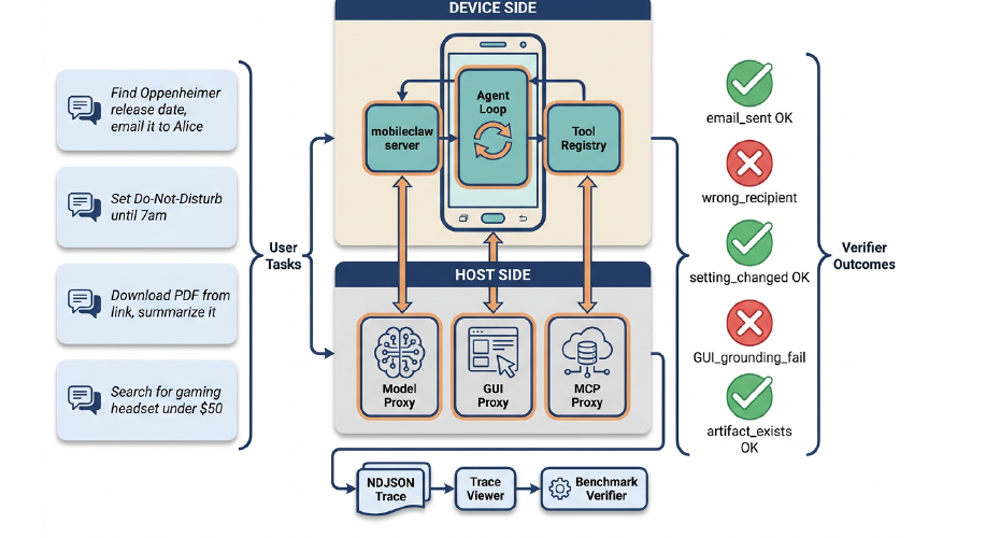
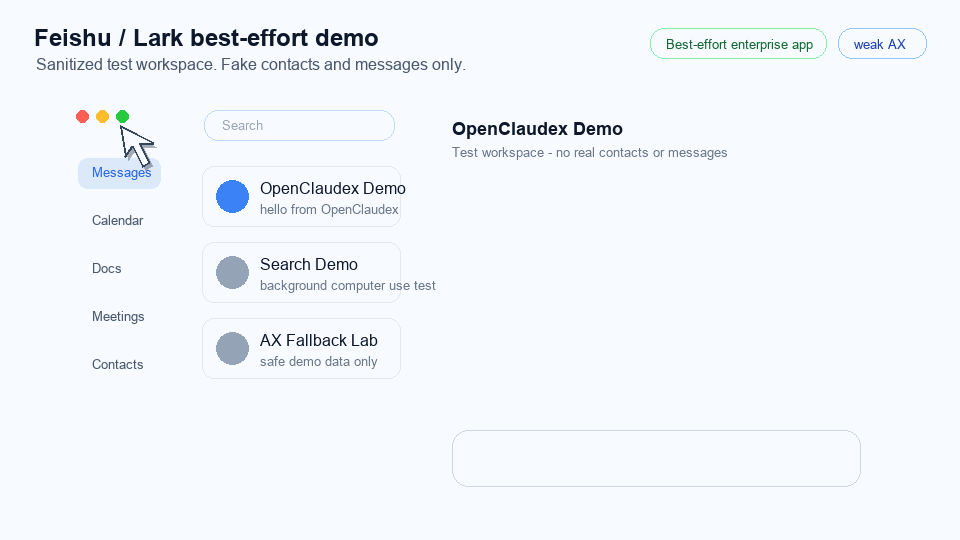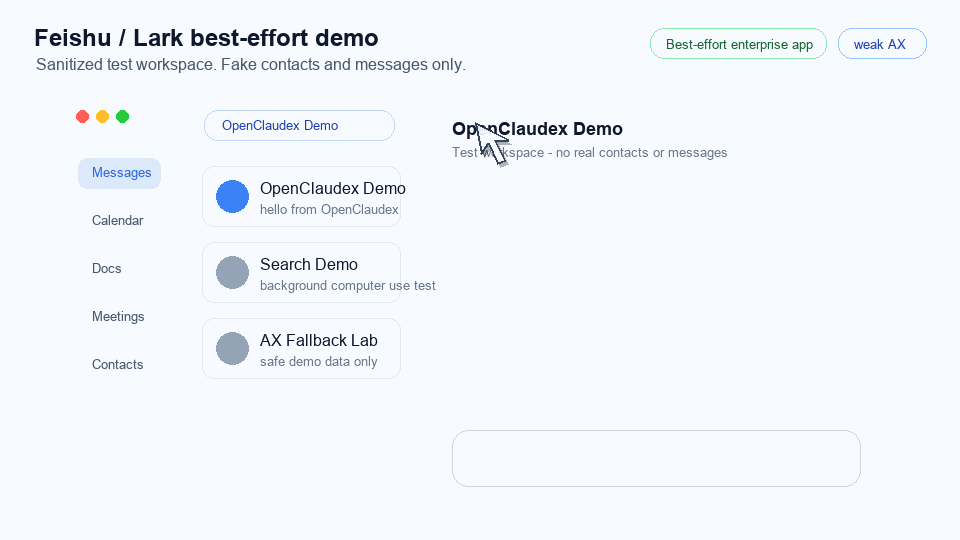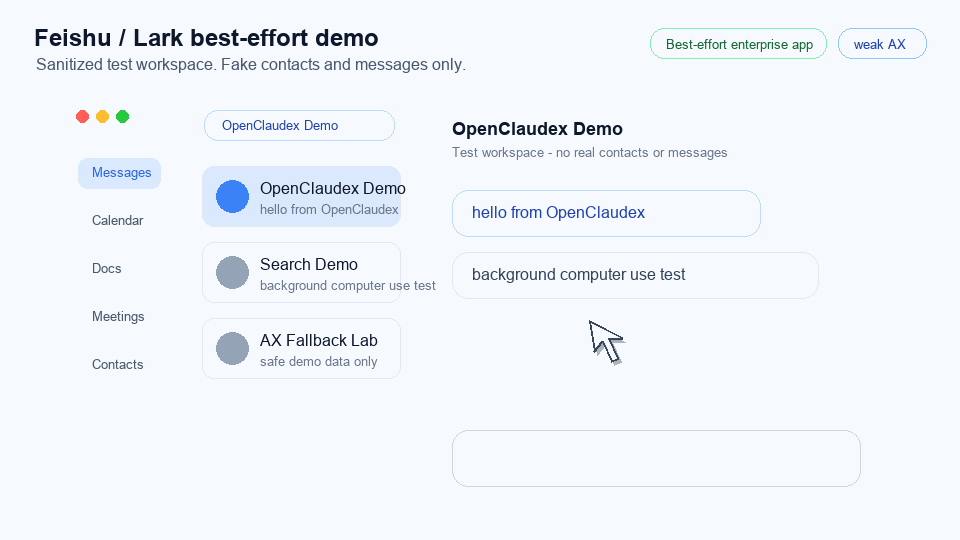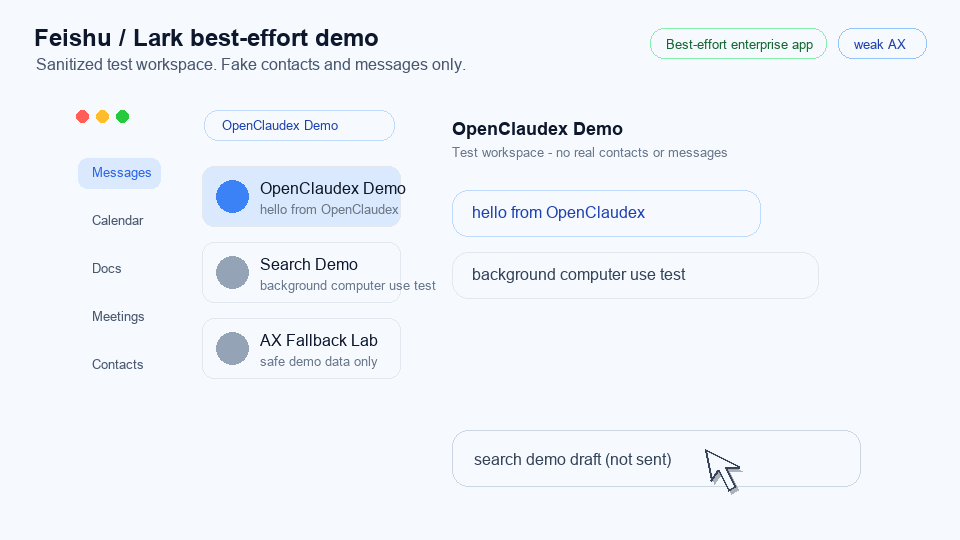
Claw-Eval (Live): A Live Agent Benchmark for Evolving Real-World Workflows
Chenxin Li†, Zhengyang Tang, Huangxin Lin, Yunlong Lin, Shijue Huang, Shengyuan Liu, Bowen Ye, Rang Li, Lei Li, Benyou Wang, Yixuan Yuan
[Project] [Paper] [Code] [AI 生成未来 | PaperAgent]
A live workflow-agent benchmark with refreshable demand signals and verifiable execution traces; 105 tasks across 22 categories, 13 frontier models, top model passes only 66.7%.
|
|
|
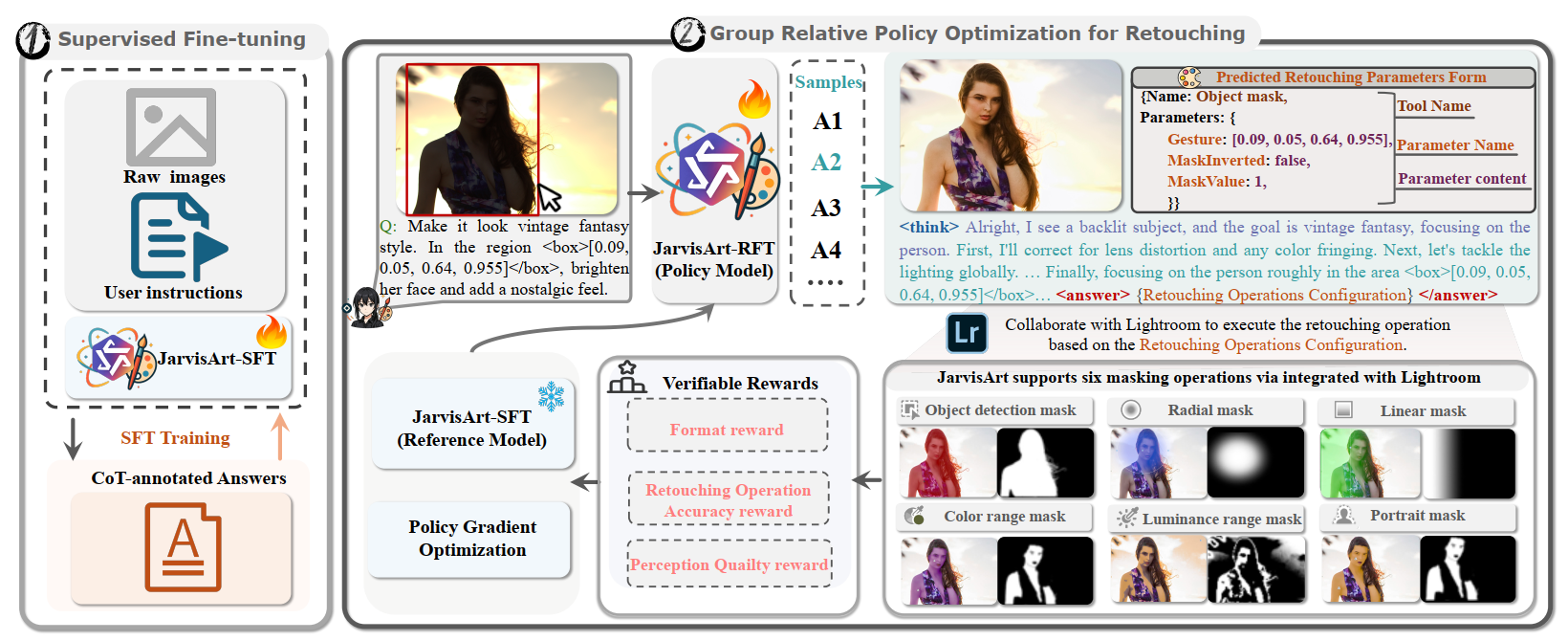
BlenderAgent: Evaluating Vision-Language Model Scene Understanding through Agentic Inverse Rendering with Blender CLI
Parker Liu*, Chenxin Li*, Zhengxin Li, Yipeng Wu, Wuyang Li, Zhiqin Yang, Zhenyuan Zhang, Yunlong Lin, Sirui Han, Brandon Y. Feng
NeurIPS 2025
[Project] [Paper] [Code]
BlenderAgent converts an input image into structured 3D scene code, executes it in Blender, and evaluates the rendered reconstruction using geometric, spatial, and appearance metrics.
|
|
|
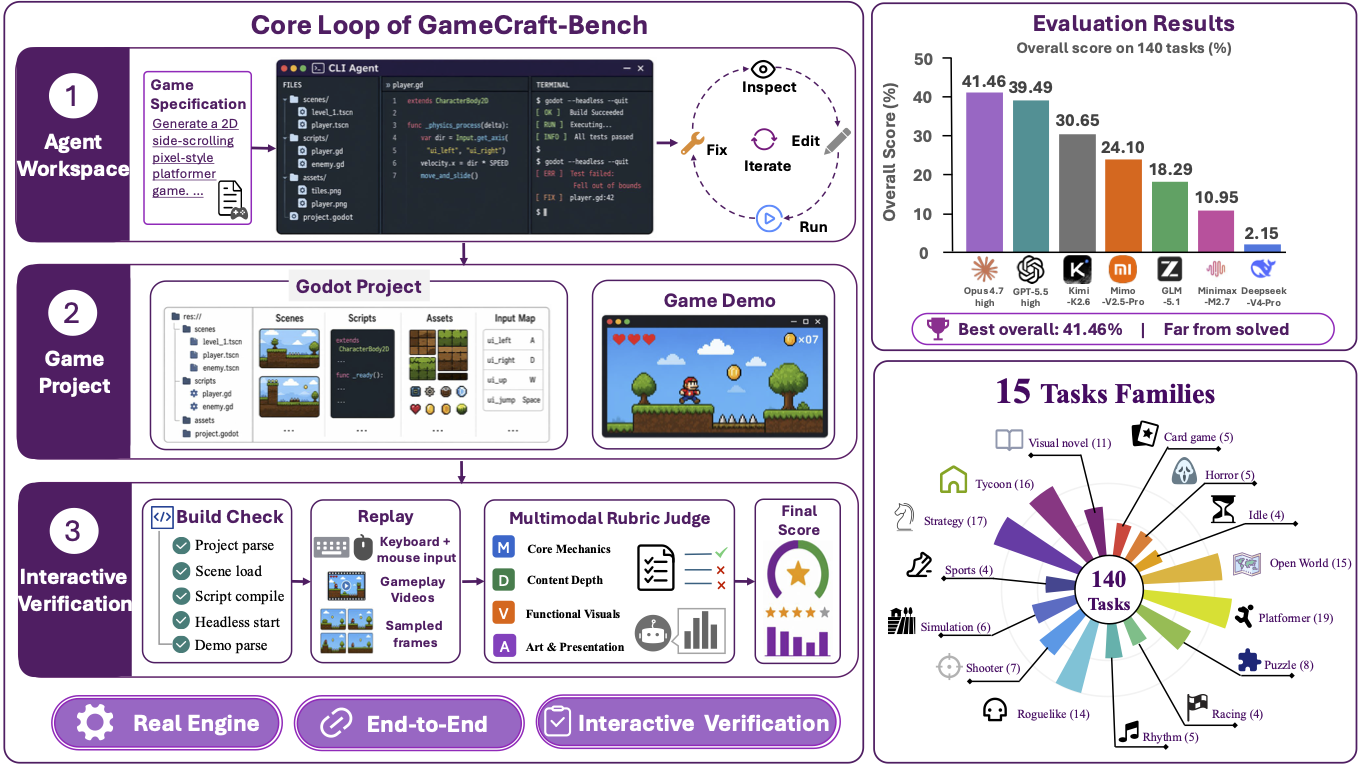
GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
Tongxu Luo, Rongsheng Wang, Jiaxi Bi, Chenming Xu, Zhengyang Tang, Jianlong Chen, Juhao Liang, Ke Ji, Shuqi Guo, Yuhao Du, Fan Bu, Wenyu Du, Xiaotong Zhang, Kyle Li, Shaobo Wang, Linfeng Zhang, Yuxuan Liu, Xin Lai, Chenxin Li, Yiduo Guo, Zhexin Zhang, Xinyuan Wang, Tianyi Bai, Ziniu Li, Benyou Wang
[Project] [Paper] [Code]
A game-generation benchmark for coding agents, with 140 Godot tasks and interactive verification of playable end-to-end game artifacts.
|
🧭 Selected Experience [LinkedIn]
- ByteDance Seed, Intern, CLI agents, frontend coding, and CLI/MCP tool-use
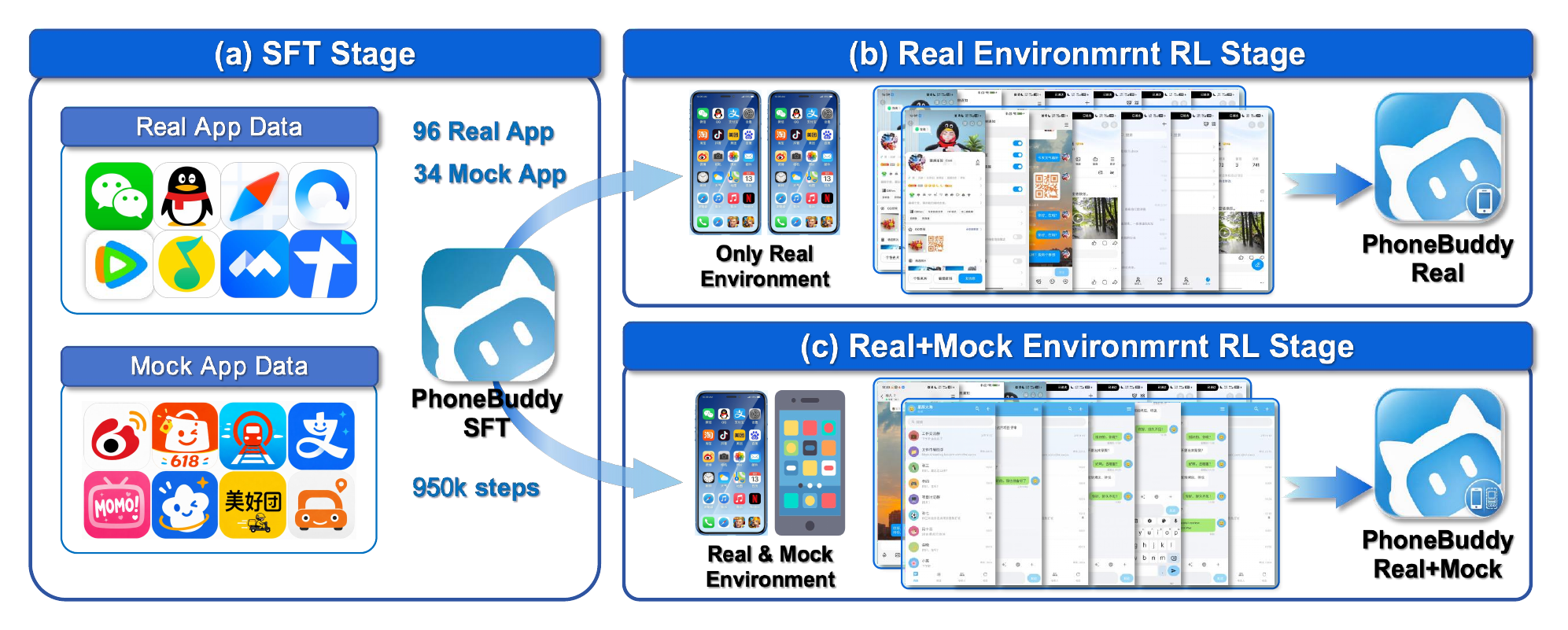
- Tencent Hunyuan, Intern, phone-use agents and live workflow-agent evaluation
- Tencent AI Lab, Intern, Blender-CLI agents and structured visual reasoning
- ScholaGO, Co-founder & Tech Lead, 2023-2024: K-12 education-agent platform, supported by HKSTP, HK Tech 300, and Alibaba Cloud
|
🎓 Professional Activities
- Workshop Organizer: AIM-FM: Advancements In Foundation Models Towards Intelligent Agents (NeurIPS 2024)
- Talks: VALSE Summit (Jun 2025) and DAMTP, University of Cambridge (Jul 2024)
- Conference Reviewer: ICLR, NeurIPS, ICML, ACL, CVPR, ICCV, ECCV, EMNLP, AAAI, ACM MM
- Journal Reviewer: Nature Machine Intelligence, PAMI, TIP, DMLR, PR, TNNLS
|
🌱 Hobbies Beyond Work
- Vibe Working: I build and use agents as daily collaborators, testing how much work and life can be wired into agent workflows.
- Reading: I read history, philosophy, and sociology to reason about people, systems, and long-term trends.
- Stock Investment: I treat investing as real-world RL: making decisions under uncertainty, learning from feedback, and allocating capital, attention, and time.
|
|